Verification of rendering results in Blender. A (not so short) story about nondeterminism and machine learning
Authors: Witold Dzięcioł, Łukasz Foniok, Magdalena Stasiewicz, Michał Szostakiewicz
Thanks to María Paula Fernández, Piotr ‘Viggith’ Janiuk, Natalia Mroszczyk, Jacek Muszyński
Golem is a trustless environment - this means that the fairness of nodes creating the network can’t be assumed. When a requestor (at least an honest one) sends a task to the network, they want to get valid results, regardless the fact that potentially some of the providers are cheating. One of the biggest challenges for Golem as a project is to provide mechanisms able to protect requestors from malicious providers.
We are focusing on two different, independent approaches to this problem. One of them is relying on the provider’s reputation — it’s less likely that a node with good reputation is going to cheat. Another idea is to check the correctness of the computation done by the provider. In this installment of our Trusted Computations Series, we will describe how Golem verifies Blender rendering results.
Theory of computation divides algorithmic problems into several classes based on the effort needed to solve them and an effort needed to tell if a given solution is correct. As Golem’s target — for now — are computationally intensive tasks we will focus on this category. In the future, when persistent tasks (a.k.a. services) are added, this may no longer be the case:
- One class consists of tasks perfectly suited for Golem — computationally intensive, but easy to verify. An example of these are proof-of-work algorithms: a lot of effort has to be put into solving the “puzzle” but once a solution is found its correctness can be checked by performing only a few operations.
- Another class are tasks which can’t be quickly verified (checking a solution takes similar amount of time to finding it). Many of the real-life algorithmic problems belong to this category. Having a problem instance and a solution doesn’t allow us to determine its correctness without performing complex computations, or even repeating the whole computation. This class includes graphics rendering.
Fleshing out the problem
3D rendering
3D rendering is the process of transforming a 3D model (scene) into a two-dimensional picture or animation. A scene contains the description of the objects present in it — geometry, optical properties, information about their movements and so on, alongside lighting, camera position, etc. Rendering is a complicated, time and resource-consuming process which usually utilizes simulations of physical phenomena and probabilistic methods like Monte Carlo. It is difficult — if not impossible — to make meaningful conclusions about the final image based in the scene’s properties without repeating at least a part of the rendering.
Blender tasks in Golem
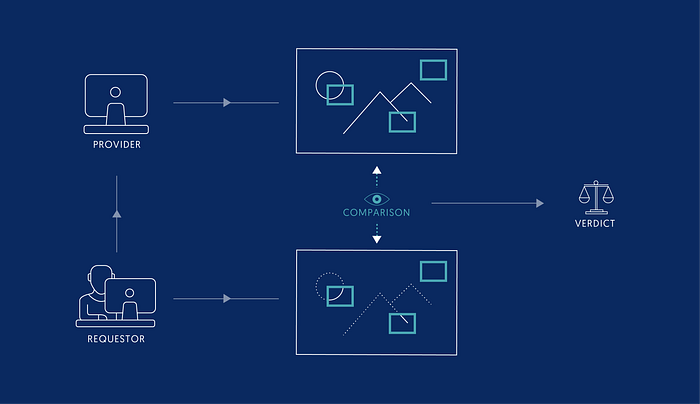
When defining a Golem Blender task, the requestor specifies the scene file and additional parameters — such as which frames they want rendered, how many samples per pixel should be used and into how many chunks (subtasks) the task should be divided. Each provider then renders a different part of the target image or animation.

After assigning a subtask to a specific provider, the requestor waits for the provider to send back the results — a bitmap (or a set of bitmaps if the subtask consisted of more than one frame). This is when the requestor will need to make sure the data received is valid.
Verification
At this point, we have a blender scene file, information about input parameters which should have been used to render it (frame numbers, resolution, number of samples per pixel to be used, etc.) and the result sent by the provider — a bitmap. Based on these, we have to either accept or reject the result. This needs to be done in a reasonable timeframe, which stands for: a significantly shorter time than the one used by the provider to get the bitmap.
Note that we are not checking if the provider actually did the computations— we only want to know whether the result is correct. A provider could have guessed the solution or generate it in any other way — this is not something we are monitoring — as long as it is correct.
There is one more noteworthy issue. Rendering is not an entirely deterministic process. Even after eliminating obvious sources of nondeterminism, such as a varying seed for random numbers generator, we can’t expect images rendered with the same parameters, but on different machines to be identical. There are small differences, invisible to a human, yet they would disqualify a simple bit-by-bit comparison.
In this nondeterministic rendering context, a question arises — what does a correctly rendered image mean? We have disqualified the approach — an image is correct if it’s identical with what I rendered on my machine”. So in order to find this answer, we decided to base ourselves on a conditional that makes the most sense: — “a result should be accepted if the difference isn’t visible to a human”. This might seem fairly obvious, but has an important implication: the line between”correct” and “incorrect” images is arbitrary.We must also be aware that, because of the nature of our problem, including the nondeterminism and the limited amount of computational effort we can put into it, we will never be able to make a 100% certain verdict. The best we can do is to find a solution which reduces mistakes to an acceptable minimum when putting the results into “correct” and “wrong” bins.
Attacks — how can a malicious provider influence a result image?
Except trivialities like sending to the requestor a bitmap in wrong resolution -we can think of a number of attacks.
The first type of attacks are rational attacks, attempts to put less effort than required into generating results and getting paid anyway. Some examples are:
- rendering with less samples than requested
- applying denoising in order to hide undersampling
The second type are irrational attacks — the provider purposely damaging an image, even if it requires substantial computational effort (e.g. rendering the valid result first, then attempting to damage it):
- applying effects like blur, smooth and sharpen to a rendered image
- enhancing colors, contrast or brightness
- adding noise
- placing watermarks or additional objects on the image
- switching channels order (for instance swapping red and green channels)
This attacks list is ever-growing — and will be increasing in number and variety probably never reaching completeness (we must admit that hackers are creative people).

Approach
As we can’t render the full image and we can’t easily extract any directly useful data from the scene file, the verdict needs to be made based on partial renders. We would then render only a few randomly chosen areas of the image, and if they all are “similar enough” to the corresponding areas of the result received from the provider, accept the image as properly computed. Otherwise it should be rejected.
Similarity metrics
What does it mean that two images are similar? There is no single answer: we can distinguish many kinds of similarity, for example two pictures can show the same shapes, but their edges might be sharper or softer. They can have the same pixel values, but the pixels can be arranged in another order, and so on. We need to measure each similarity type, that’s why mathematical properties which correspond to certain kinds of similarity are required to be identified — similarity metrics.
Comparing images is nothing new. There have been many approaches to this, in various forms — for example, one of the common instances is estimating the quality of a compressed image as compared to its original version. Here it is possible to reuse some of the existing metrics. However, metrics have to be tailored to both the investigated characteristic of the image (“similarity kind”), and the type of the defect we are trying to detect. We can’t expect one metric to solve all our problems.
Transforms
We may also need to enhance some features of the image or extract data not directly accessible from it. A function — transform — can be applied to the image to achieve it. Examples are:
- Fourier transform — probably the most famous one, widely used in sound processing, however sometimes also helpful in dealing with images
- wavelet transform — the idea behind it is similar to Fourier’s, but in general it’s better for image processing
- edge detection
- edge enhancing
- contrast enhancing
Feature
A pair consisting of a transform and a metric is called feature. The idea is to apply the same transform to both compared images and then calculate the metric’s value on the transformed results. The transform can be an identity and simply return the unaltered input image, which results in the metric being calculated on the original images.
After conducting laborious experiments we decided to use following features:
- structural similarity index (SSIM) — one of the widely known and frequently used metrics. Its result gives a general idea about the relative quality of the images and their overall similarity
- RGB histograms’ correlation — this is pretty self-explaining, allows to detect defects related to colours (manipulations of colours intensity, contrast, brightness, …)
- mean squared error (MSE) of wavelet transform results — this is actually not one, but three metrics, for which we perform wavelet transform on both images, divide the spectra into three psuedofrequency ranges, and for each of them we calculate mean squared error to get a number telling how much the spectra differ:
- low pseudofrequencies tell us something very important — they describe the biggest structures visible on the image, basically telling
what is shown on the picture
- medium pseudofrequencies describe details of objects visible on the image
- high pseudofrequencies — they detect structures of the size of a few pixels. This is also key, as through this way we can detect defects like noise or undersampling - MSE of bitmaps with applied edge detection transform. An edge detection algorithm is run on the compared images, then their MSE is calculated. This is another way of checking if the images picture the same objects (shapes), but it sometimes can also notice unwanted noise and undersampling
- mass center distance — for each channel we calculate positions of mass centers (pixels’ intensities are considered their masses) in both images. For each channel we take the distances of the mass centers in the first and second image, then we choose the channel having maximal value of it, and this value is our metric. We do it in both horizontal and vertical direction (internally we call them max X mass center distance and max Y mass center distance). This helps to detect defects like incorrect colors distribution, additional objects placed on the image or parts of image being removed.


Decision process
We know how to mathematically describe characteristics of compared images. The next step would be to prepare an algorithm able to choose between the “similar enough” and “not similar enough” label for a pair of images (or a set of the features’ values — a layer of abstraction can be put here).
In its simplest version one could say “OK, I require all of the features’ values to be less (or more — depending on the metric) than a particular threshold set. If any of them doesn’t fit into the range defined, the image is rejected”. This isn’t a bad approach, but a new question pops up — how should we define the thresholds? We don’t have intuition on how exactly differences between pictures affect metrics values. For instance, we know that “the bigger SSIM the more similar are compared images”, but there is little to no chance that anyone would be able to look at a pair of images and estimate well their SSIM.
This is where machine learning comes in — Golem doesn’t have to choose the thresholds. All one has to do is to prepare a set of features values labeled “should accept”, “should not accept” and pass it to an algorithm which constructs rules. The rules are constructed to give the best possible classification of the input (training) set. Along with the input set, additional parameters are passed to the teaching algorithm. This allows a certain degree of control over the training process.
There are several classifier models, but we used one of the simplest — a decision tree. The choice was made due to its clarity and readability.
Dataset
In order to train a decision tree, a large and representative set of properly labeled data is needed. This is often a problem, because in most cases it means that the set must be labelled manually by humans. In this particular case this issue was not faced — the data (images) was digitally generated. The starting point was choosing model Blender scenes — from quite simple to complicated, production ones. Then we rendered them all with varying numbers of samples — from very low, around 1–100 samples (for most scenes this is indeed too low) to very high, more than needed. The result was a series of images, from which some of them were valid — above some number of samples the difference between differently sampled images is unnoticeable — and some were visibly undersampled.
For each scene, we defined two thresholds for number of samples — one of them above through which all the images should be accepted when being compared to each other and one below through which all images should be rejected when compared to images from above the first threshold. The images that were between these two thresholds were ignored, as we cannot be certain about what labels they should have.
The next step was generating defects in copies of properly sampled images. This happens under the assumption that the requestor knows what they’re doing and requests a proper number of samples, so our reference image — the fragment rendered locally to compare with the received result — is never undersampled. An image with defects should always be rejected when compared to its original version.
The dataset in this case consists of around 7,500,000 pairs of images (or, more precisely, pairs of image fragments sized 10%x10% of the original resolution, cropped from the renders). The set was divided into training and test subsets in a 2:1 ratio. It was assured that the same scene is never present in both training and test sets.

Results
The decision tree in the current (0.17.0) Golem version is nine levels deep, consists of 237 nodes and has the following effectiveness:


Results discussion
Our goal was to have the correct rejections rate as high as possible, with the false rejections rate not exceeding 1%.
A few defects drew attention due to their significantly worse results: blur, smooth, sharpen and undersampling. The main reason for this is suspected to be that as in our dataset we treated these very strictly,many of our example images used for teaching and testing these defects are barely visible, even when zoomed in closely.
These results tell what the classifier accuracy is for an image fragment with a defect. The accuracy of the classification of a whole image will be different and depending on the fragments chosen for comparison.
What’s next?
There is still a wide range of improvements that can be done. More featurescan be tested. Fragments for comparison could be chosen not randomly, but based on the characteristic of the received bitmap: many scenes have a lot of “boring” areas which can’t give us much information — like uniform background, on which undersampling sometimes can’t be detected. We could also render the whole image in a smaller resolution or with a very small number of samples — which doesn’t take too much time — and try to compare the images’ global features (for instance,to check if the pictures show similar shapes).
Another idea is to allow redundant computations. Right now jobs in Golem are totally separate — each provider renders a different part of the final image. However, some jobs could partially overlap. This way we could make the verification process faster on the requestor’s side, as they wouldn’t have to locally render the fragments used for comparison.
Based on the providers’ reputation we could estimate which results the requestor received are more and which are less trustworthy. Nodes supporting SGX to generate the reference image can be also added.
We hope this overview of verification methods, results and approaches was useful to you. We are continuing the work to find more robust solutions, but it takes time and testing.
Our work on the redundant verification methods is underway, we will share the results soon. Thank you for following — we look forward to your feedback and questions while we write our next installment.
We encourage you to ask questions and discuss with the community on the #general channel on Rocket Chat.